I’ve been reading about the aggressive pricing strategies in the AI space for months, but seeing a trend play out in industry articles is completely different from watching it hit your own wallet in real-time for the first time.
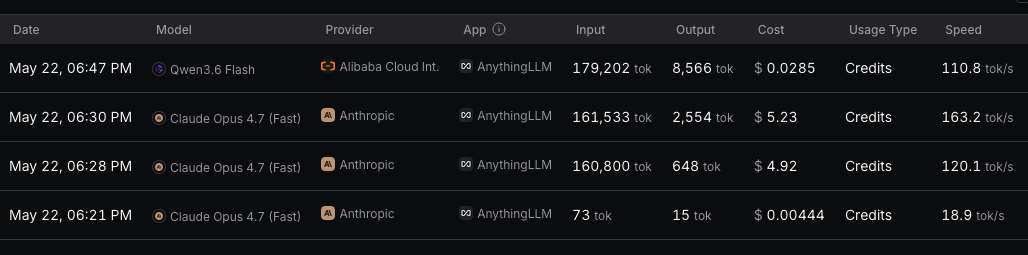
Last night, I was testing local setups for some personal data parsing, feeding large context dumps into AnythingLLM via OpenRouter. When I pulled up my usage dashboard to audit the session expenses, the stark reality of the asymmetric price war between legacy frontier models and the new wave of optimized engines was right there on my screen.
Two consecutive prompts tell the entire story:
-
Claude Opus 4.7 ($5.23)
- Payload: 161,041 input tokens / 2,364 output tokens
-
Qwen 3.6 Flash ($0.028)
- Payload: 179,200 input tokens / 8,512 output tokens
The 2.8-Cent Eye Opener
Look closely at those metrics. The data payload I passed to Qwen was actually 11% larger than the one I gave to Claude, and it generated more than triple the analytical output. Yet, it cost exactly 2.8 cents compared to Claude’s $5.23.
Running that heavy dataset through Claude essentially cost 186 times more than running it through Qwen.
Rethinking My Workflow
This single observation completely changes how I architect my local workflows moving forward. When dealing with large text dumps, raw context processing, or initial cleaning passes, the play is obvious:
-
Heavy Lifting to the Commoditized Layer: Let highly optimized, cost-efficient models like Qwen or DeepSeek Flash handle the bulk ingestion and structural sorting for fractions of a penny.
-
Surgical Execution for Premium Logic: Reserve heavy, premium reasoning models strictly for the final step where deep logical auditing or strategic conclusions are required.
Witnessing this extreme pricing gap first-hand emphasizes the value of utilizing open-source frontend wrappers. Keeping your data storage local while having the flexibility to dynamically switch API backends means you can completely bypass the premium tax on massive context files, optimizing your computational efficiency down to absolute zero.